


As you might know, when creating a 3D games, models play an huge part for everything. Even if the engine is one of most important part, what is displayed is even more important.
Some idea about a 3D RPG circle around my head faster and faster with the developpement of color glib. The engine get to a point that it might be usefull for displaying vivid world and monster, in a semi-iteractives framerates
However, my skill with blender and texturing are close to zero : I can retouch some model and rigs the at least, but to create one from ground up, I fail miserably. I could tackle some texturing with the huge image:texture bank I have from ripped game, but don't expect much though.
What do I need ? Well, 3D models ranging from the main character to some monster (even if those can be ripped for testing, and replaced much much later). Ideally those should be low poly enough to be displayed, but I could handle this part (I've have several nice technique to lower poly count, so it isn't much important).
One model I would love to see is a main character. Well, to be honest, I have several idea of what he/she could look like, but I won't describe it extensively if nobody might create it
So, this lead to the main question : who feel he could create a 3D model for a fantasy based 3D RPG in low poly with texture ?
Some idea about a 3D RPG circle around my head faster and faster with the developpement of color glib. The engine get to a point that it might be usefull for displaying vivid world and monster, in a semi-iteractives framerates
However, my skill with blender and texturing are close to zero : I can retouch some model and rigs the at least, but to create one from ground up, I fail miserably. I could tackle some texturing with the huge image:texture bank I have from ripped game, but don't expect much though.
What do I need ? Well, 3D models ranging from the main character to some monster (even if those can be ripped for testing, and replaced much much later). Ideally those should be low poly enough to be displayed, but I could handle this part (I've have several nice technique to lower poly count, so it isn't much important).
One model I would love to see is a main character. Well, to be honest, I have several idea of what he/she could look like, but I won't describe it extensively if nobody might create it
So, this lead to the main question : who feel he could create a 3D model for a fantasy based 3D RPG in low poly with texture ?






































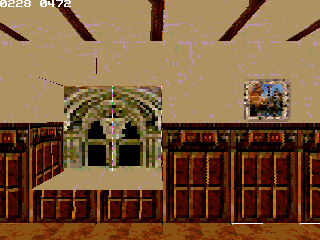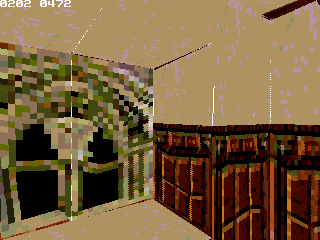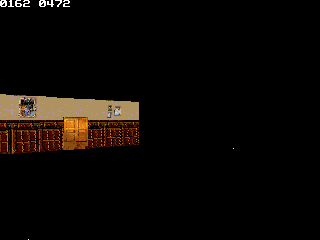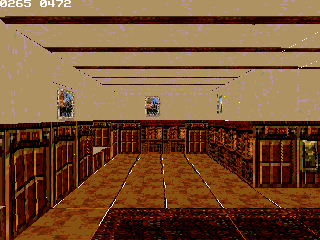







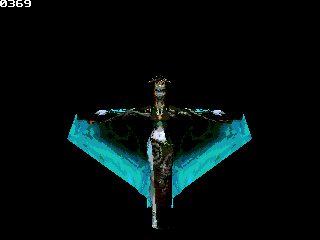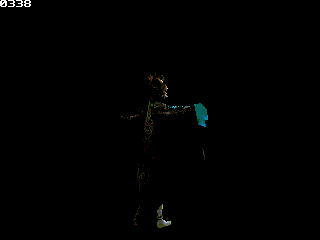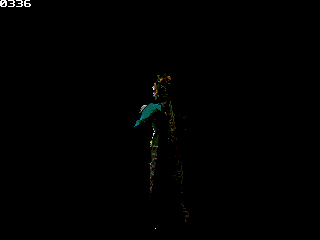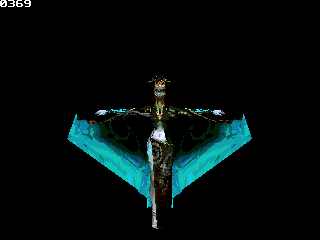




 ; and include gLib's variable definition.
; and include gLib's variable definition.

