

The first tool to be able to downgrade is now out https://tiplanet.org/forum/archives_voir.php?id=1398736 

This section allows you to view all posts made by this member. Note that you can only see posts made in areas you currently have access to.
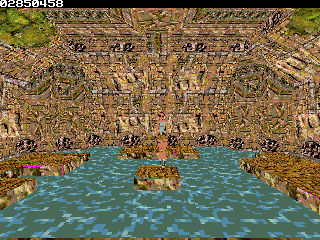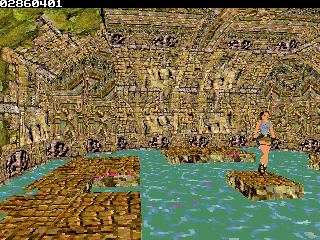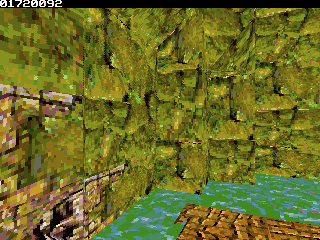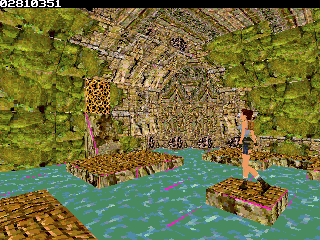
 Even considering the fact I have no (or limited vs PS1) lightning, the simple fact that it run *only* 8x slower (30fps vs 4-3fps) make me happy
Even considering the fact I have no (or limited vs PS1) lightning, the simple fact that it run *only* 8x slower (30fps vs 4-3fps) make me happy  (since the ez80 definitly doesn't have PSX hardware )
One of the primary optimization one can do in such context is bounding boxes, test a whole sub level part against frustrum with 8 vertices et skip it enterily if it is outside. Given that the library can handle different stream of polygons/vertex from different location and doesn't expect only one consecutive stream, this is a very interesting thing to do. Second optimization that may be doable is to reduce the far plan visibility, ie how far can you see polygons. PS1 used this technique very often, using some fog. We won't be able to do fog here, but it is still a good thin to have given that depth is computed for sorting anyway. Third reside in library optimization itself, which aren't at all done ), the complexity may be pretty high. I also may start to do a more advanced use of the library for following demo because well I want more speed obviously.
(since the ez80 definitly doesn't have PSX hardware )
One of the primary optimization one can do in such context is bounding boxes, test a whole sub level part against frustrum with 8 vertices et skip it enterily if it is outside. Given that the library can handle different stream of polygons/vertex from different location and doesn't expect only one consecutive stream, this is a very interesting thing to do. Second optimization that may be doable is to reduce the far plan visibility, ie how far can you see polygons. PS1 used this technique very often, using some fog. We won't be able to do fog here, but it is still a good thin to have given that depth is computed for sorting anyway. Third reside in library optimization itself, which aren't at all done ), the complexity may be pretty high. I also may start to do a more advanced use of the library for following demo because well I want more speed obviously.
 How will you handle lightning with custom palette ?
How will you handle lightning with custom palette ?
